
大多数 RAID 级别使用冗余来确保阵列的可靠性。冗余允许阵列在其中一个驱动器发生故障时继续运行而不会丢失数据。这项技术旨在保护数据,但如果使用不当,则可能导致数据丢失。
在本文中,我们将探讨"不当重建"的问题,这可能使 RAID 数据恢复变得非常困难甚至不可能。这是 RAID 存储用户常犯的错误,他们试图自行恢复阵列的功能。只有在恢复失败后,他们才会求助于数据恢复服务。我们将更详细地探讨人们为什么会犯这个错误。
作为一个例子,我们将使用最容易理解的级别之一——RAID-1(镜像)。在此类阵列中,所有成员(通常有两个)都存储数据的完整副本。如果一个驱动器发生故障,所有数据都在另一个驱动器上。
正确重建
首先,让我们看看"正确重建"——存储系统开发人员最初设想的场景。
步骤 1 — 阵列初始化
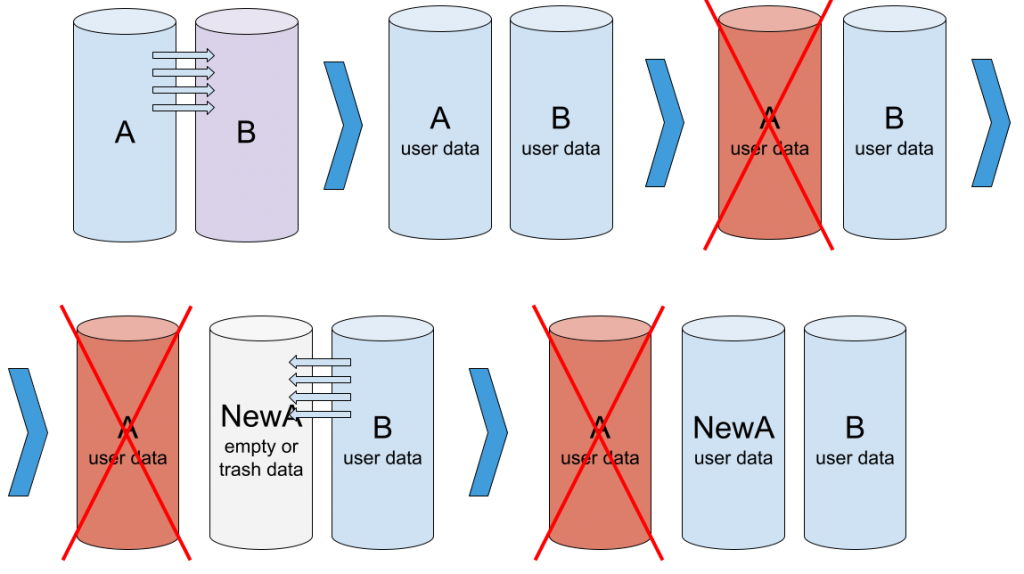
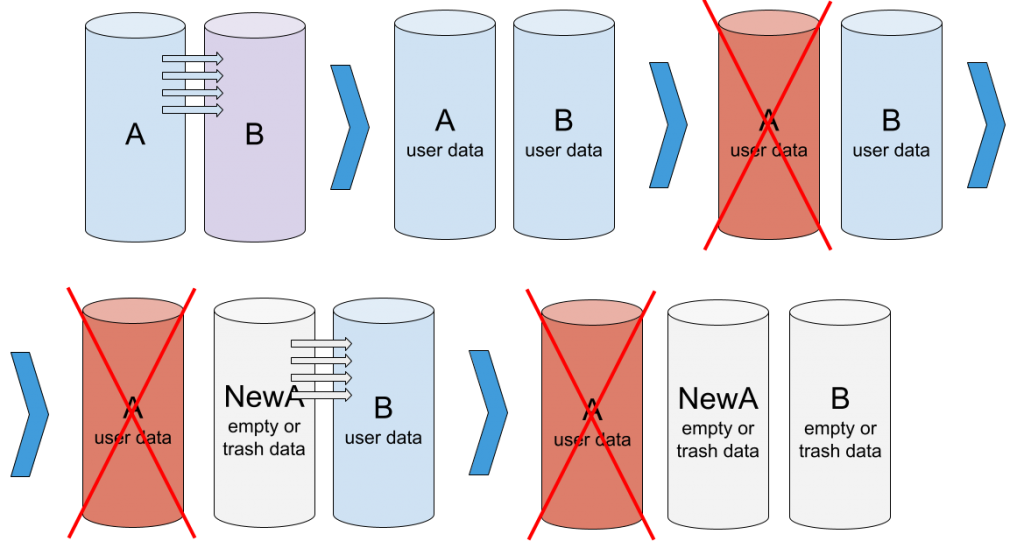
一切都始于初始化阵列。我们取两个新驱动器,并基于它们创建一个新阵列。控制器无法确定成员上的数据是否相同,因此它启动初始化过程,将数据从驱动器 A 复制到驱动器 B(这是最常见的行为,但对于某些控制器可能不同)。
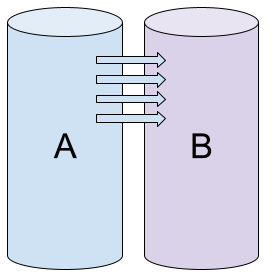
阵列初始化:两个驱动器工作正常,但包含不同的数据。正在执行从 A 到 B 的复制。
步骤 2 — RAID 启动并运行
阵列已初始化,两个驱动器工作正常,并包含相同的数据。
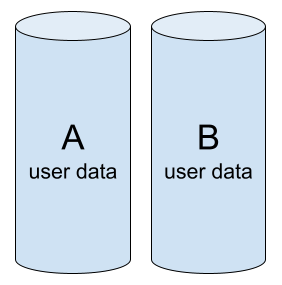
功能正常的 RAID-1:成员健康且相同(A = B)
步骤 3 — 由于单个驱动器故障导致 RAID 降级
在某个时刻,阵列的一个成员发生故障,例如成员 A。由于冗余,阵列仍在运行,数据仍然可用。但是,阵列不再提供相同的可靠性——另一个驱动器的故障将导致数据丢失。此状态称为阵列降级。
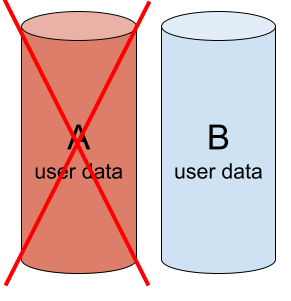
阵列降级:成员 A 有缺陷并从阵列中排除。成员 B 正常。
步骤 4 — 更换并恢复成员
为了使阵列恢复正常,我们移除驱动器 A 并在其位置添加一个新驱动器 NewA。NewA 上的数据与 B 上的数据不匹配。因此我们需要重建阵列——将数据从 B 复制到 NewA。
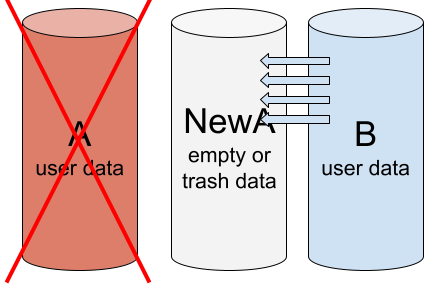
重建阵列:在成员 A 的位置添加了一个驱动器 NewA。正在将数据从 B 复制到 NewA。
步骤 5 — 再次获得正常工作的 RAID
此过程结束时,我们将再次拥有一个由两个驱动器组成的工作阵列。
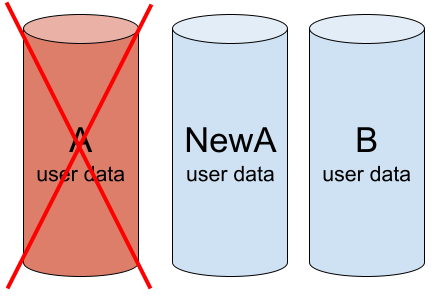
重建完成,阵列功能正常:NewA 和 B 健康且包含相同数据。A – 故障,未使用。
正确重建序列一览
初始化 > 正常运行 > 降级 > 重建 > 正常运行
这是 RAID 控制器开发人员和用户在驱动器故障情况下都预期的事件序列。
不当重建
不幸的是,阵列降级并不总是得到正确处理。没有执行正确的重建,而是执行了重新初始化,这可能导致数据丢失。
让我们详细描述这一事件链。
步骤 1-3 – 初始化、正常运行、降级
前三个步骤完全相同,因此我们不加评论。
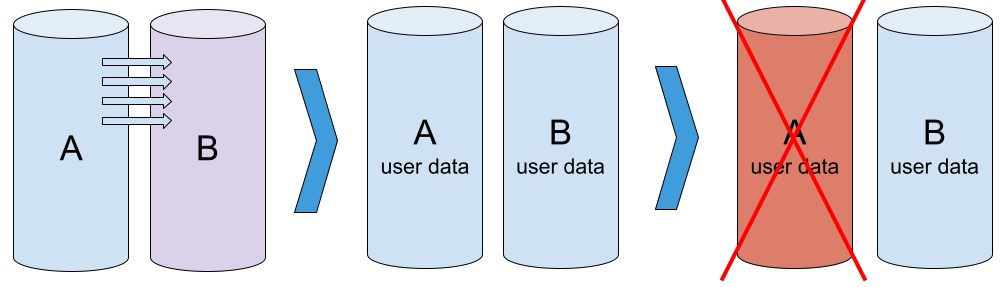
初始化 > 正常运行 > 降级
步骤 4 — 驱动器更换和阵列初始化
在此步骤发生错误——启动了阵列初始化而不是重建。数据将从一台驱动器复制到另一台驱动器,但复制方向可能是错误的,然后新的无用数据将覆盖旧的所需用户数据。
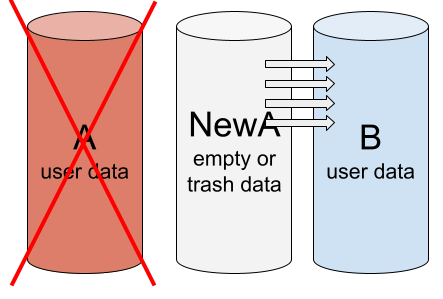
初始化代替重建:用 NewA 代替成员 A。执行初始化。数据从 NewA 复制到 B。
故障的原因通常是人为因素。 对于大多数用户来说,阵列降级是非常罕见的事件,他们并不总是能自信而简洁地操作。用户并不总是清楚地理解存储管理系统中的这个或那个命令意味着什么:"添加阵列、创建阵列、组装阵列、初始化阵列、重建阵列、恢复阵列、重构阵列"等等。还可以加上压力和匆忙的因素。在这种条件下,很容易犯错误。
步骤 5 – 形式上工作正常的 RAID,但没有用户数据
初始化后,我们得到一个形式上工作正常的 RAID,但没有任何用户数据。
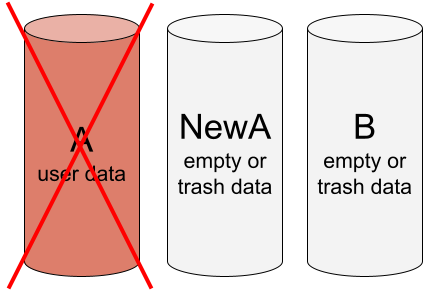
形式上功能正常的阵列:NewA 和 B 健康且相同(NewA = B),但不包含正确数据。只有故障驱动器 A 仍然包含正确数据。
不当重建序列一览
初始化 > 正常运行 > 降级 > 不当初始化 > 数据丢失
因此,数据保护机制导致了数据丢失。获取正确数据的唯一方法是从故障成员 A 恢复数据。
结论
让我们总结一下结果:
-
RAID-1 阵列中的数据必须同步(在所有成员上相同)。
-
初始化是在首次用户数据写入阵列之前进行的初始同步过程。数据从哪里复制到哪里并不重要。
-
重建也是一个数据同步过程,但这里方向非常重要,因为存在所需数据(在旧成员上)和不需要的数据(在新成员上)。
-
有时 RAID 存储用户会犯错误,并运行初始化而不是重建。在这种情况下,用户数据可能被不需要的数据覆盖。然后他们才向数据恢复服务寻求帮助。这种情况在数据恢复行话中通常被称为不当重建或简称重建。
在本文中,我们专注于最容易理解的 RAID 级别,但同样的问题也普遍存在于其他具有冗余的级别,如 RAID-5 或 6。对于数据恢复专业人员来说,了解根本问题、能够识别它们并理解它们如何影响恢复数据的能力非常重要。